Download image files from website with Python.
The module request can help us to fetch contents of web page, we can use BeautifulSoup to parse the html string and collect all interesting elements, download images by relevant URLs which are filtered by our script.
import requests, sys, webbrowser, bs4, urllib
if __name__ == "__main__":
res = requests.get( "http://www.nipic.com/index.html" )
res.raise_for_status()
soup = bs4.BeautifulSoup( res.text, features='html.parser' )
elements = soup.select( 'img' )
elements = list(set(elements))
count = min( 5, len( elements ) )
for i in range(1, count):
urlStr = elements[i].get('src')
file = urlStr.split( '/' )[-1]
index = file.find( '.' )
index = index + 4
file = file[0:index]
print( "Download: " + urlStr + " => file: " + file )
r = requests.get( urlStr, stream=True )
with open( file, 'wb' ) as f:
f.write( r.content )
print( "status code: ",r.status_code )
print( "content-type: " + r.headers['content-type'] )
print( "encoding: ", r.encoding )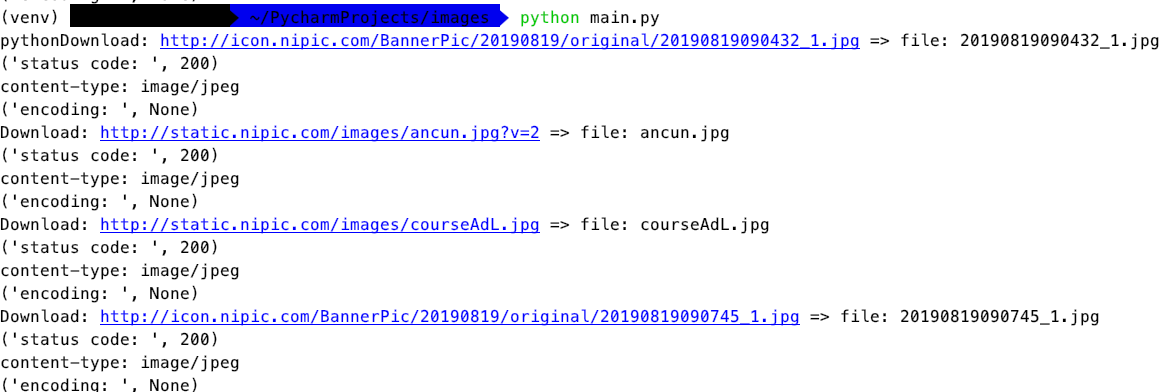
Make it more flexible, transfer URL in command line:
C:\Users\Stephen\AppData\Local\Microsoft\WindowsApps\python3.10.exe D:\Images\fetch.py https://www.zhihu.com/question/65562234/answer/2830211890Improved code:
import requests, sys, webbrowser, bs4, urllib
if __name__ == "__main__":
if len(sys.argv) < 2:
print( "usage: scriptPath URL" )
exit(1)
URL = sys.argv[1]
res = requests.get( URL )
res.raise_for_status()
soup = bs4.BeautifulSoup( res.text, features='html.parser' )
elements = soup.select( 'img' )
elements = list(set(elements))
count = len( elements )
for i in range(1, count):
urlStr = elements[i].get('src')
if urlStr == None:
continue
file = urlStr.split( '/' )[-1]
index = file.find( '.' )
if index < 1:
continue
index = index + 4
file = file[0:index]
r = requests.get( urlStr, stream=True )
with open( file, 'wb' ) as f:
f.write( r.content )
print( "Download: " + urlStr + " => file: " + file )
# print( "status code: ",r.status_code )
# print( "content-type: " + r.headers['content-type'] )
# print( "encoding: ", r.encoding )